By now, you’ve probably heard the term server-side tracking tossed around in martech discussions, sometimes in the same breath as “server-side tagging”, often incorrectly. But as privacy laws tighten, browsers get smarter (and stingier with data), and ad blockers become the default, this approach to tracking is quietly becoming more than a fringe solution. It’s starting to look like a necessity.

In this article, we’ll break down what server-side tracking actually is, how it differs from server-side tagging, why identifiers and consent still matter, common myths around privacy compliance, and how various tools, including Salespanel, help implement it in real-world B2B workflows. Whether you’re a marketer, a product lead, or an engineer, this guide will help you understand when and why to adopt server-side tracking, and what to watch out for.
What is server-side tracking really? And should we all be moving there?
At its core, server-side tracking refers to the practice of collecting and logging user activity data, such as pageviews, form submissions, and conversions, directly from your backend server, rather than relying on scripts executed in the user’s browser. Unlike client-side tracking, where the browser is responsible for sending data to analytics or marketing platforms, server-side tracking moves that logic to your own infrastructure. This means your server collects the data based on events it knows have happened (like a confirmed form submission or a successful login) and sends it directly to your analytics systems or stores data in your own big data systems for that matter, with full control over how, when, and what gets tracked.
In contrast to server-side tagging, which is often about relaying events to third-party ad platforms from a managed server container, server-side tracking is about building a clean, privacy-safe, and reliable source of behavioral truth right from your application’s backend. You’re not just routing pixels; you’re owning the capture and context of each event from the moment it happens.
I think it will be really important to understand how the client-side tracking is different from server-side tracking. Let’s first talk about that.
Tracking 101: From the Client Side to the Server Side
For the better part of the past two decades, client-side tracking has been the backbone of digital analytics. It’s the reason you know how many users visited your site, which pages they landed on, what buttons they clicked, and where they dropped off. If you’ve ever installed a Google Analytics script, Salespanel pixel or a Facebook Pixel, you’ve engaged in client-side tracking.
Here’s how it works: When someone visits your website, their browser loads JavaScript tracking scripts embedded in the page. These scripts monitor user actions, like clicks, form fills, scrolls, and send that data directly from the user’s browser to external services like Google Analytics, Salespanel, or ad platforms. It all happens in real-time and largely depends on the user’s browser executing those scripts successfully.
In many ways, client-side tracking made modern web analytics possible. It was easy to implement, worked out-of-the-box for most use cases, and gave marketers and product teams a live pulse on user behavior. But as the web evolved, so did its limitations.
Where Client-Side Tracking Starts to Crack
Over the last few years, cracks have begun to show in the client-side model. Modern browsers like Safari and Firefox introduced privacy-first features like Intelligent Tracking Prevention (ITP), which limit the lifespan of cookies and block third-party trackers altogether. Ad blockers are now used by a significant portion of internet users, often preventing client-side scripts from even loading.
Moreover, client-side tracking is inherently fragile. If a user bounces quickly, tracking scripts might not have time to fire. If there’s a network hiccup, your event might never reach its destination. And then there’s the matter of data security and compliance, when scripts are run in the user’s browser, they often collect raw data that gets sent off to multiple vendors with little oversight, posing real risks in a post-GDPR world.
This is where server-side tracking enters the picture.
Server-Side Tracking: A More Reliable, Privacy-Conscious Alternative
Server-side tracking flips the traditional model. Instead of relying on the user’s browser to send tracking data, it shifts that responsibility to your own server, the one that powers your website or app. In this model, your backend becomes the trusted source of truth for what happened during a user session.
Because server-side tracking runs entirely in your own native server infrastructure, it’s immune to ad blockers and browser limitations. It also allows you to filter, anonymize, or enrich data before it ever leaves your environment, putting you in full control of what’s being tracked and where it’s going, something that’s increasingly important in a world of privacy regulations.
A Matter of Ownership and Accuracy
The fundamental difference between client-side and server-side tracking isn’t just technical, it’s also a philosophical one.
Client-side tracking is easy, fast, and scalable, but you’re largely dependent on browsers, and your data can be filtered, blocked, or lost without you even knowing.
Server-side tracking is harder to implement initially, but you own the pipeline. The data is cleaner, the process is more reliable, and your organisation is better positioned to meet compliance requirements, especially when user trust is on the line.
In essence, moving to server-side tracking is a signal that you’re maturing in how you treat your analytics, not just as a tactical tool, but as a strategic approach that deserves care, structure, and accountability.
Server-side tracking still needs an identifier
One of the biggest misconceptions about server-side tracking is that moving event collection to the backend somehow removes the need for identifiers. It doesn’t. If you want to understand who did what and connect multiple actions to the same person or account, you still need a way to identify them. Server-side tracking may give you more control and reliability, but it doesn’t solve the fundamental challenge of user recognition. It simply shifts that challenge to a different part of the stack. Let’s unpack what that means and why identifiers are still the backbone of any meaningful tracking setup, server-side or not.
Why Identifiers Are Still Essential (Even Server-Side)
When someone visits your website or uses your app, you need a way to tell:
- Are they a new visitor or a returning one?
- Are they logged in, or do you only know them via session/cookie?
- If they fill a form, how do you connect that back to their earlier activity?
This “connection” between actions is made possible by identifiers. Whether you’re tracking server-side or client-side, you still need to carry forward some kind of unique identifier across requests.
Common Types of Identifiers in Server-Side Tracking
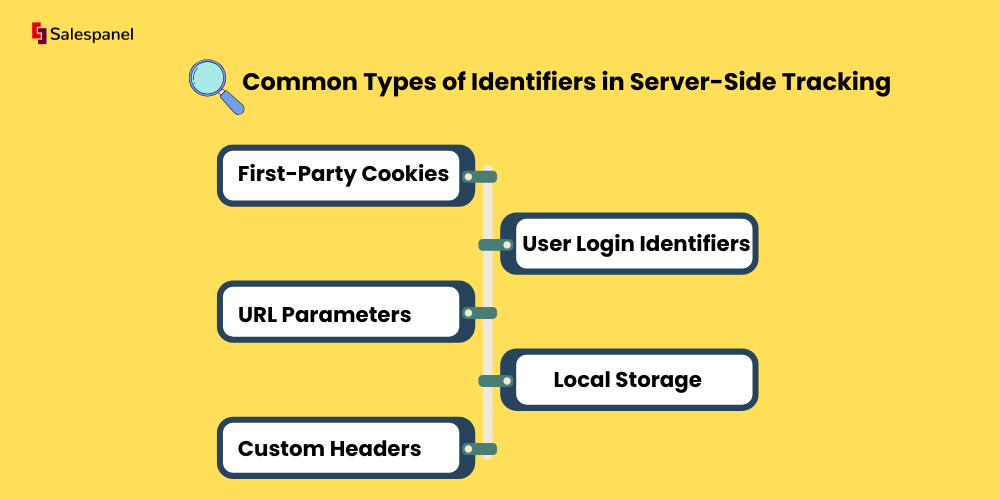
1. First-Party Cookies (Set by You)
Even with server-side tracking, your frontend needs to set a first-party cookie (e.g., visitor_id=abc123). This cookie gets read by the browser and passed along with every request, and you use it server-side to stitch sessions and actions together.
This is the most common setup in hybrid models:
- Frontend sets a cookie
- Backend reads the cookie and uses it as an identifier when sending data to analytics
2. User Login Identifiers
If someone logs in, that’s gold. You can now attach all events to a user ID in your database.
- Pageview before login → Cookie-based identifier
- Signup → Associate the cookie with a new user ID
- Logged-in sessions → Use user ID directly for all server-side tracking
3. URL Parameters (UTMs, GCLID, FBP, FBC, etc.)
Many ad platforms append identifiers in URLs (e.g., ?gclid=xyz from Google Ads). You must capture and persist these, either as cookies or session metadata, to send back during conversion events (especially important for ad attribution).
4. Local Storage (with JS bridge)
You can also use JS to store visitor IDs in local storage and then pass them to your backend via AJAX or custom headers.
5. Custom Headers or Auth Tokens
In web apps or mobile apps, you might use headers (e.g., Authorisation: Bearer xyz) to identify users. These can be parsed by your server to resolve a user ID.
The Myth: “Server-side tracking doesn’t need consent because it’s on our server.”
Now that we’ve established that server-side tracking still relies on identifiers, it’s time to address an equally important, and dangerous, misconception. Many teams assume that because tracking happens on their own server, they no longer need user consent. The logic goes: “If we’re not using third-party scripts or cookies, we must be in the clear.” But that’s not how data privacy laws work. Consent requirements are tied to the use of personal data, not where the tracking happens. And if you’re storing identifiers or linking behavior across sessions, you’re processing personal data. Let’s clear the air on this common myth before it becomes a legal liability.
The Reality: Consent Is Tied to Identifiers, Not Just Technology
Many companies move to server-side tracking under the belief that it gives them full control and avoids consent banners.
That illusion falls apart as soon as you use a persistent identifier, whether a cookie or a user ID.
Here’s a quick test:
Are you able to tie two pageviews from the same user together?
→ If yes, you’re tracking personal behavior over time. You need consent.
Server-side tracking gives you control over how you track. Consent laws define whether you can track.
So the real advantage of server-side tracking is this:
- You can delay tracking until after consent.
- You can remove PII before sending data to vendors.
- You can respect user preferences with precision.
But you’re not off the hook just because the pixel is gone.
It doesn’t matter where your tracking logic runs, browser or server. If you are using identifiers to recognize users, especially over time, you are processing personal data under most data protection laws.
This includes:
- First-party cookies
- Persistent identifiers (e.g., visitor ID, CRM ID, hashed emails)
- Device or session fingerprints
- Any cross-session tracking that builds a user profile
If your server-side logic tracks behaviour and ties it back to a user, that’s subject to GDPR, ePrivacy, CCPA, and other similar regulations. Just because the tracking is done on your own infrastructure doesn’t exempt you from needing consent.
- GDPR defines personal data as “any information relating to an identified or identifiable natural person.” That includes cookies, device IDs, and session identifiers.
- If you’re setting a cookie or reading one (even a first-party one), you need prior consent in jurisdictions like the EU unless it’s strictly necessary (e.g., for login or checkout).
- If you’re sending identifiers to ad platforms (even from your server), that’s still personal data processing and subject to user consent and opt-out rights.
| Activity | Consent Required? | Why? |
| Tracking logged-in users with user ID | ✅ Yes | User ID is personal data |
| Sending purchase events to Meta via Conversions API | ✅ Yes | Includes personal identifiers (email, fbp, etc.) |
| Tracking anonymous users using a cookie ID | ✅ Yes (in EU) | Cookie used for tracking, not strictly necessary |
| Measuring button clicks via frontend + cookie bridge | ✅ Yes | Involves tracking behavior tied to ID |
| Collecting aggregated pageview counts with no ID | ❌ No | No personal data used or retained |
Let’s summarise the pros and cons now.
The Pros of Server-Side Tracking
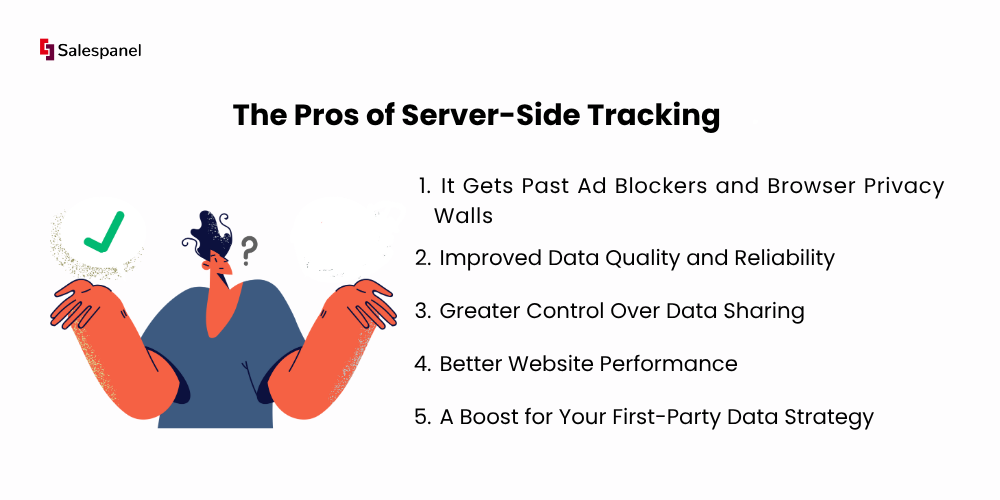
1. It Gets Past Ad Blockers and Browser Privacy Walls
Ad blockers don’t block your server. Nor does Safari’s ITP or Firefox’s ETP. When your server sends the data directly to your vendors, it sails right past those barriers.
“With client-side tracking, we were seeing nearly 30% data loss from Safari users. Server-side changed that overnight.”
A growth marketer at a DTC brand
2. Improved Data Quality and Reliability
Client-side tracking is fragile. A user bounces quickly? Their events might not fire. A network blip? That purchase event never reaches your analytics.
Server-side is less prone to failure. The user clicks “Buy”, your server processes the order, and immediately fires a “Purchase” event. No middleman, no drama.
3. Greater Control Over Data Sharing
In an age where compliance is currency, server-side lets you intercept, filter, and sanitise data before it ever hits a third-party platform.
Want to remove PII? Done. Want to block users from the EU entirely? Your server can do that. You’re no longer at the mercy of third-party scripts behaving in unknown ways.
4. Better Website Performance
Every script on your site adds load time. Fewer scripts = faster site = better UX and SEO.
By offloading tracking logic to the backend, you reduce dependency on bloated libraries like gtag.js, Meta Pixel, and others.
5. A Boost for Your First-Party Data Strategy
Server-side tracking plays beautifully with first-party identifiers. You can stitch together sessions more accurately, even when third-party cookies are dead.
Think of it as a way to future-proof your attribution models and customer journey analytics.
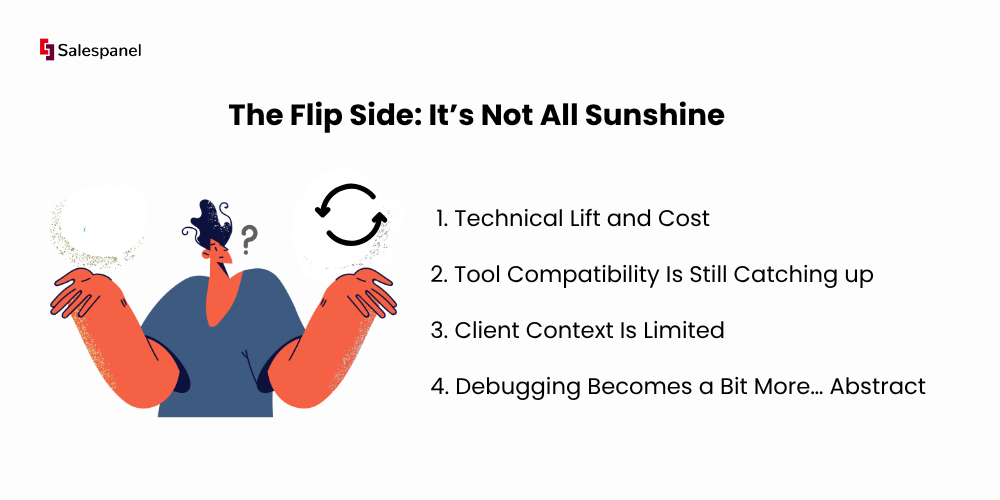
The Flip Side: It’s Not All Sunshine
Let’s not pretend this is plug-and-play.
1. Technical Lift and Cost
You’ll need backend infrastructure, developers to maintain it, and potentially a cloud setup to scale it.
If you’re not already set up with Google Tag Manager Server-side (GTM SS) or a cloud function that routes and transforms data, you’re looking at a decent initial investment, in both time and money.
2. Tool Compatibility Is Still Catching Up
Not every third-party platform is server-side friendly. Facebook and GA4 are ahead (which brings us to server side tagging, more on that soon…), but some CRM or marketing platforms still expect JavaScript-based events. You might have to hybridize your setup.
3. Client Context Is Limited
Some interactions (like scroll depth or heatmaps) require the browser’s viewport context. Server-side can’t capture these natively, so a hybrid (client + server) model is often the most pragmatic solution. Salespanel gives you a hybrid solution, more on that soon at the end of the article.
4. Debugging Becomes a Bit More… Abstract
Forget “Inspect Element” and watching network requests in DevTools. Debugging server-side requires proper logging, observability tools, and structured testing.
So, Should You Move?
It depends on your stack, your goals, and your stage of growth.
- If you’re losing data to ad blockers or browser privacy policies, you should seriously consider it.
- If privacy compliance is a legal (or brand) concern, server-side puts you in control.
- If you’re running a high-scale site with real conversion volume (or to improve custom audience match rates), the performance and data reliability gains can be substantial.
But if you’re a scrappy team without backend resources, you may want to look at managed server-side platforms (like Segment Functions, RudderStack, or GTM Server-Side) as a stepping stone.
So What the Heck Is Server-Side Tagging?
One of the most common sources of confusion in martech today is the blurred line between server-side tracking and server-side tagging. While the terms are often used interchangeably, especially by marketers, they refer to two fundamentally different things, both in terms of architecture and purpose. Yes, they can coexist in a modern stack, but lumping them together leads to flawed assumptions, especially around data ownership and compliance.
As we discussed server-side tracking is focused on data collection. It involves sending user interaction data, such as pageviews, form submissions, logins, or purchases, directly from your backend server to your analytics or data tools. This approach makes sure that you have a better data tracking coverage without any sampling, is immune to ad blockers and browser restrictions like Intelligent Tracking Prevention (ITP), and allows organizations to capture only confirmed backend events (e.g., a successful signup) rather than relying on what the browser thinks happened. It’s commonly used to feed clean, structured data into platforms like GA4, Salespanel, or internal BI systems, and is usually implemented using backend SDKs, REST APIs, or CDPs like Segment and RudderStack.
On the other hand, server-side tagging is not about collecting data, it’s about routing it. Specifically, it refers to firing third-party marketing tags (such as Facebook Pixel or Google Ads conversion tags) from a secure server environment rather than directly from the browser. The main objective here is to improve conversion attribution and audience matching accuracy in ad platforms, especially in a post-cookie, privacy-restricted world. Server-side tagging setups, often built using tools like GTM Server-Side, Stape, or Tealium, act as a relay: they receive frontend data (e.g., from JavaScript or cookies), process it on the server, and forward it to ad vendors with cleaned and enriched identifiers like email hashes or UTM parameters.
To put it simply, server-side tracking helps you collect better data, while server-side tagging helps you use that data more effectively in marketing ecosystems.
| Scenario | Use Server-Side Tracking? | Use Server-Side Tagging? |
| You want to track logins to your SaaS app | ✅ Yes | ❌ No |
| You want to record “signed up” in GA4 | ✅ Yes | ✅ Possibly (for ad conversion) |
| You want to tell Facebook a lead converted | ❌ Not enough alone | ✅ Yes |
| You want to send a “Contact Form Submitted” event to Salespanel | ✅ Yes | ❌ No |
| You want to build a retargeting audience in LinkedIn | ❌ Not directly | ✅ Yes |
| You want to remove PII before sending to Google Ads | ✅ Yes | ✅ Yes (via SS container) |
Now that we’ve unpacked the what and why of server-side tracking and cleared up the confusion with tagging, it’s time to explore the tools that make it all work in practice. Whether you’re building your own pipeline from scratch or looking for plug-and-play integrations, the tooling landscape has matured significantly.
To make things easier, we’ll break down the ecosystem into three major categories, based on how much control you want and how your organization handles data. If you haven’t seen this kind of thematic categorization earlier, make sure to forward this article to your marketing team to help them enhance their understanding of the topic! So here we go:
- Infrastructure-based platforms – for teams who want full ownership and flexibility to build custom pipelines.
- Customer Data Platforms (CDPs) – that offer built-in support for server-side event ingestion and routing.
- Analytics tools with server-side capabilities – for enriching your existing analytics stack with backend-triggered data.
Let’s dive into the options that are powering modern, privacy-conscious tracking architectures.
1. Infrastructure-Based Tools (Do-It-Yourself / Maximum Flexibility)
These are ideal for teams with engineering resources who want deep control over data capture, transformation, and routing.
🔹 Google Tag Manager Server-Side (GTM SS)
- What it is: A self-hosted container to run Google tags on a server (often on Google Cloud App Engine).
- Key Features:
- Server-side execution of GA4, Google Ads, Facebook, and other marketing tags.
- Works by routing frontend events to a tagging server (e.g., https://ss.mysite.com), which then forwards them to vendors.
- Supports cookie rewriting for longer retention (e.g., overcoming ITP limits).
- Ideal for: Marketers who already use GTM and want to move tags off the client while retaining flexibility.
🔹 AWS Lambda / GCP Cloud Functions / Azure Functions
- What it is: Pure code-based serverless infrastructure to implement your own tracking logic.
- Key Features:
- Build your own event collection endpoints.
- Route events to Mixpanel, GA4, Facebook, etc., via API.
- Full control over event schemas and compliance.
- Ideal for: Teams that want maximum ownership, custom logic, and control over data handling.
2. CDPs (Customer Data Platforms) With Server-Side Support
These tools give you a central data pipeline with both frontend and backend SDKs, simplifying implementation without sacrificing power.
🔹 Segment (by Twilio)
- What it is: A leading CDP that allows you to collect, transform, and route data from any source to any destination.
- Key Server-Side Features:
- Backend SDKs (Node, Python, Java, Ruby, etc.) for logging events from your server.
- Ability to track events like “user signed up” or “subscription failed” directly from your backend.
- Schema enforcement, identity stitching, and transformations before sending data to downstream tools.
- Bonus: You can combine client-side and server-side events using the same user ID.
🔹 RudderStack
- What it is: An open-source alternative to Segment with a similar philosophy.
- Key Server-Side Features:
- Supports server-side SDKs and cloud-mode destinations.
- Offers full control over identity resolution and data governance.
- Easier to self-host or run in a private cloud than Segment.
- Bonus: More engineering-friendly, with Git-like versioning for event schemas.
🔹 Snowplow Analytics
- What it is: A behavioral data platform for building your own fully structured, compliant data pipeline.
- Key Server-Side Features:
- Collects granular, structured event data from the frontend or backend.
- Offers flexibility to run pipelines in your cloud (AWS/GCP).
- Full ownership of data, no black boxes.
- Best for: Data science-heavy orgs that want raw, event-level data for advanced modelling.
3. Analytics Tools with Server-Side Capabilities
Some analytics and product tools now support direct ingestion of server-side events.
🔹 Mixpanel
- What it is: A product analytics tool for user behaviour tracking.
- Key Server-Side Features:
- Server-side libraries for multiple languages.
- Can receive backend-triggered events (e.g., subscription created).
- Useful for combining client-side engagement with backend conversions.
🔹 Amplitude
- What it is: A product intelligence and user journey analysis platform.
- Key Server-Side Features:
- Server-side API and SDKs for logging events.
- ID merge and cohort building based on user actions from both the browser and the backend.
- Works well for B2B SaaS companies analysing post-login behaviour.
🔹 GA4 Measurement Protocol
- What it is: Google Analytics 4’s server-side API.
- Key Features:
- Allows you to send events from your server directly to GA4.
- Can be used to bridge gaps when client-side data is blocked.
- Often used with GTM Server-Side or directly via HTTP requests.
| Tool | Type | Ideal For | Open Source | Server-Side SDKs | Built-In Tag Routing |
| GTM Server-Side | Infra/Tagging | Tag managers in a privacy-safe way | ❌ | ❌ (API-level only) | ✅ |
| Segment | CDP | Mid to large orgs, quick rollout | ❌ | ✅ | ✅ |
| RudderStack | CDP | Developer-led teams | ✅ | ✅ | ✅ |
| Snowplow | Infra/CDP | Full ownership and modelling | ✅ | ✅ | ❌ |
| Mixpanel | Analytics | Product analytics with server events | ❌ | ✅ | ❌ |
| GA4 + MP Protocol | Analytics | Basic analytics with server events | ❌ | ✅ | ❌ |
Where Does Salespanel Fit in the Server-Side Tracking Landscape?
Salespanel is not a traditional tag manager, it’s a real-time B2B visitor intelligence and lead qualification platform. That said, its deep tracking system and REST API offer functionality that aligns with server-side tracking goals, just tailored for B2B demand gen, ABM, and qualification rather than broad web analytics.
Salespanel Deep Tracking = Hybrid First-Party Tracking
Salespanel’s deep tracking relies on a JavaScript SDK running on the frontend, but unlike typical client-side tools (like Google Analytics), it uses first-party data models:
- Tracks sessions, pageviews, company data, email interactions, and more, and links them to identifiable visitors.
- Uses first-party cookies (not 3rd-party ones), which are more resilient against browser restrictions and ad blockers.
- Supports custom event tracking (e.g., “Watched demo,” “Clicked pricing”), events that can also be mirrored through the REST API from the backend.
So while technically initiated on the frontend, it’s engineered to behave like server-side solutions in key ways:
- Survives cookie restrictions.
- Can identify anonymous-to-known transitions (once a form is filled).
- Ties multiple sessions to the same account-level identity (company, not just user).
- Tracks returning visitors with the highest accuracy
The Server-Side Angle: Salespanel’s REST API
Here’s where Salespanel gets closely aligned with server-side tracking:

This is especially useful for:
- Post-conversion events (e.g., subscription activated, invoice paid).
- Backend-triggered events that have no frontend equivalent (e.g., CRM status changed, feature used in SaaS app).
- Enriching visitor journeys with guaranteed backend data (e.g., lead score increased based on 3rd-party enrichment or internal usage metrics).
🔑 Example Use Cases:
- A lead schedules a call via Calendly → Your server receives webhook → You send a Scheduled Call activity to Salespanel via REST API.
- A product trial hits a usage milestone → Backend triggers: Reached Milestone event for that visitor’s profile.
- A sales rep marks a deal as “Lost” in CRM → You push a Disqualified event to Salespanel for full journey visibility.
This hybrid model , deep client-side capture + flexible server-side enrichment, enables a B2B marketer or sales team to have a clean, consolidated timeline of account activity, which few tools do well.
| Capability | Salespanel Supports? | How? |
| Client-side tracking | ✅ | Deep tracking JS SDK (first-party) |
| Server-side event triggering | ✅ | REST API for custom activities |
| First-party ID resolution | ✅ | Email-based & cookie-based identity |
| CRM/webhook integration | ✅ | Push activity data from backend |
| Tag routing to ad platforms | ❌ (by design) | Not a tagging platform |
| Privacy-first tracking | ✅ | GDPR-compliant, no 3rd-party cookies |

Final Thoughts
Server-side tracking is no longer just a technical curiosity, it’s becoming a necessity in a world shaped by ad blockers, browser privacy restrictions, and evolving data regulations. But the shift isn’t just about moving from browser scripts to server logic; it’s about taking ownership of your data pipeline, improving accuracy, and ensuring compliance. Yet, it’s crucial to understand that server-side tracking doesn’t eliminate the need for identifiers, and wherever identifiers are involved, user consent remains essential. Marketers also need to stop conflating server-side tracking with server-side tagging; the former is about secure, backend-triggered data collection, while the latter is about routing that data to ad platforms in a privacy-safe way. Tools like GTM Server-Side, Segment, and RudderStack help you build robust tracking pipelines. Still, platforms like Salespanel bring a practical, B2B-focused approach by combining deep client-side tracking with flexible server-side enrichment via API. The future isn’t about abandoning client-side, it’s about building a hybrid tracking architecture that’s resilient, privacy-conscious, and built for precision.
We hope that you liked this in-depth article from our team. Please let us know if you would like to learn more about related topics. We can be reached out to from our support desk or simply ping us on the live support chat.



